Claude Fable 5 wraca globalnie po blokadzie: co się zmieniło
Anthropic przywraca Claude Fable 5 globalnie od 1 lipca 2026 po zniesieniu kontroli eksportu. Wyjaśniamy, co się zmieniło, jak działa nowy klasyfikator i kiedy wrócą dostawcy chmurowi.

Anthropic opublikował specyfikację i metodologię benchmarków w komunikacie z dnia premiery Claude Fable 5 i Mythos 5. Trzy dni później sytuacja modelu zmieniła się zasadniczo.
9 czerwca 2026 roku Anthropic zrobił coś, czego jeszcze kilka tygodni wcześniej nie chciał robić: udostępnił publicznie model klasy Mythos. Nazwał go Claude Fable 5 i przedstawił jako najmocniejszy model firmy przeznaczony do ogólnego użytku.
Aktualizacja: Fable 5 wraca po zniesieniu kontroli eksportu
30 czerwca 2026 roku Anthropic opublikował komunikat „Redeploying Fable 5”. Firma poinformowała, że kontrole eksportu na Fable 5 i Mythos 5 zostały zniesione, a Claude Fable 5 wraca globalnie od 1 lipca 2026 roku.
Przywrócenie obejmuje Claude Platform, Claude.ai, Claude Code i Claude Cowork. Dostęp przez AWS, Google Cloud i Microsoft Foundry ma wracać później, gdy partnerzy chmurowi zakończą własne procesy przywracania usług.
W praktyce oznacza to, że historia Fable 5 ma trzy etapy:
- 9 czerwca: premiera Fable 5 i Mythos 5;
- 12 czerwca: czasowe wstrzymanie dostępu po dyrektywie rządu USA;
- 30 czerwca / 1 lipca: zniesienie kontroli eksportu i globalny powrót Fable 5.
Anthropic wyjaśnia, że 12 czerwca nie było w stanie wiarygodnie weryfikować obywatelstwa użytkowników w czasie rzeczywistym, dlatego w praktyce musiało wyłączyć Fable 5 szerzej, niż wynikało to z samego zakresu dyrektywy. Po jej zniesieniu model może wrócić dla użytkowników globalnie.
Firma utrzymuje, że problem, który doprowadził do sporu, dotyczył wąskiego obejścia zabezpieczeń, a nie uniwersalnego jailbreaku. Anthropic twierdzi też, że przetestowane zachowanie nie pokazywało unikalnych możliwości Mythos-klasy, bo podobne proste podatności potrafiły wskazać również słabsze, publicznie dostępne modele. Jednocześnie firma wdrożyła nowy klasyfikator, który według jej danych blokuje opisane zachowanie w ponad 99% przypadków.
Dalsza część artykułu dokumentuje możliwości, ceny, zasady retencji i zabezpieczenia modelu. Fragmenty dotyczące dnia premiery warto czytać razem z aktualizacją: Fable 5 wraca globalnie, ale dostęp do Mythos 5 pozostaje ograniczony do zatwierdzonych organizacji.
To nie jest po prostu kolejny Opus z wyższym numerem. Fable 5 otwiera piątą generację modeli Claude i ma pracować nad problemami, których wcześniejsze modele nie potrafiły utrzymać w pamięci, rozłożyć na etapy albo samodzielnie doprowadzić do końca. Anthropic mówi o zadaniach trwających nie godziny, lecz nawet kilka dni: migracjach dużych repozytoriów, złożonym researchu, analizie dokumentów, projektowaniu oraz pracy wielu agentów.
Premiera ma jednak drugą, równie ważną warstwę. Pod tą samą architekturą kryją się dwa produkty:
- Claude Fable 5 jest modelem dostępnym publicznie, ale objętym dodatkowymi klasyfikatorami bezpieczeństwa.
- Claude Mythos 5 ma te same bazowe możliwości, lecz część ograniczeń została w nim wyłączona. Dostęp otrzymają jedynie zatwierdzeni partnerzy, między innymi uczestnicy programu Project Glasswing.
To właśnie napięcie między możliwościami a kontrolą jest najciekawszym elementem tej premiery.
Fable 5 w skrócie
- model API:
claude-fable-5,- okno kontekstowe: 1 milion tokenów,
- maksymalna odpowiedź: 128 tysięcy tokenów,
- cena: 10 USD za milion tokenów wejściowych i 50 USD za milion wyjściowych,
- adaptive thinking jest zawsze aktywny,
- dostęp w dniu premiery: Claude, Claude Code, API i najważniejsze platformy chmurowe,
- obowiązkowa retencja danych przez 30 dni.
Czym Claude Fable 5 różni się od Mythos 5
Fable 5 i Mythos 5 korzystają z tego samego modelu bazowego. Różnica nie polega więc na tym, że jeden z nich jest „mądrzejszy”, a drugi „słabszy”. Różnią się sposobem udostępnienia oraz zakresem zabezpieczeń.
Anthropic uznał, że możliwości nowej generacji w cyberbezpieczeństwie, biologii i chemii są wystarczająco zaawansowane, aby mogły zwiększyć możliwości również źle przygotowanych użytkowników. Dlatego Fable 5 analizuje każde zapytanie dodatkowymi klasyfikatorami.
Jeżeli system wykryje treść z obszaru ofensywnego cyberbezpieczeństwa, zaawansowanej biologii, chemii lub prób wydobywania możliwości modelu, odpowiedź może zostać obsłużona przez Claude Opus 4.8. Użytkownik zobaczy informację o zmianie modelu.
Według danych Anthropic ponad 95% sesji nie uruchamia fallbacku. W typowej pracy z kodem, dokumentami, analizą lub projektowaniem Fable 5 ma więc zachowywać możliwości zbliżone do Mythos 5. Różnica staje się istotna w domenach objętych dodatkowymi ograniczeniami.
Przed zawieszeniem Mythos 5 pozostawał modelem dla zweryfikowanych organizacji. Miał początkowo trafić do partnerów Project Glasswing zajmujących się obroną infrastruktury i wykrywaniem podatności. Anthropic planował również ograniczony program dla badań biologicznych.
Specyfikacja: milion tokenów i odpowiedzi do 128 tysięcy
Fable 5 obsługuje domyślnie milion tokenów kontekstu. Nie jest to eksperymentalny nagłówek ani droższy próg uruchamiany dopiero po przekroczeniu 200 tysięcy tokenów. Całe okno jest rozliczane według standardowej stawki.
| Funkcja | Claude Fable 5 |
|---|---|
| Identyfikator API | claude-fable-5 |
| Okno kontekstowe | 1 mln tokenów |
| Maksymalna liczba tokenów wyjściowych | 128 tys. |
| Tryb rozumowania | Adaptive thinking, zawsze aktywny |
| Cena wejścia | 10 USD / mln tokenów |
| Cena wyjścia | 50 USD / mln tokenów |
| Odczyt z prompt cache | 1 USD / mln tokenów |
| Batch API | 5 USD wejście / 25 USD wyjście |
| Retencja danych | 30 dni |
Milion tokenów nie oznacza, że model powinien przy każdym zadaniu otrzymywać całe repozytorium albo archiwum firmy. Długi kontekst zwiększa możliwości, ale nie zastępuje selekcji materiału. Największą wartość daje tam, gdzie agent musi przez wiele etapów wracać do wcześniejszych ustaleń, notatek, wyników narzędzi i plików projektu.
Fable 5 korzysta wyłącznie z adaptive thinking. Nie można całkowicie wyłączyć rozumowania, można natomiast kontrolować jego głębokość parametrem effort. Surowy tok rozumowania nie jest udostępniany. API może zwrócić jego czytelne podsumowanie, jeśli integracja o nie poprosi.
Benchmarki: największy skok w kodowaniu i długich zadaniach
Anthropic porównuje Fable 5 i Mythos 5 z Claude Opus 4.8, GPT-5.5, Gemini 3.1 Pro oraz wcześniejszym Mythos Preview.
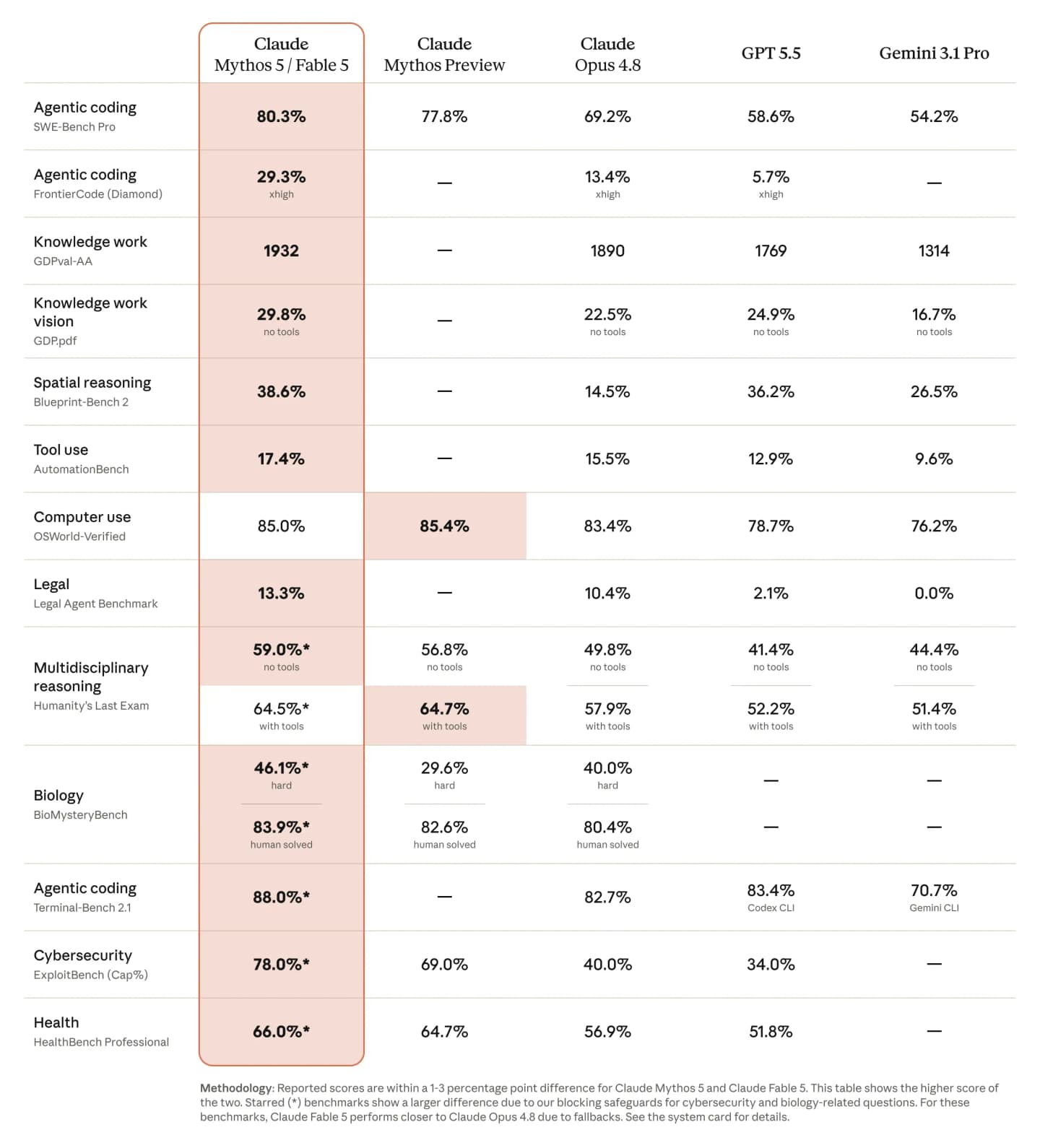
Tabela benchmarków opublikowana przez Anthropic. W większości testów wyniki Fable 5 i Mythos 5 różnią się o 1–3 punkty procentowe, dlatego pokazano wyższy wynik. Gwiazdka oznacza testy, w których zabezpieczenia Fable mogą powodować większą różnicę.
Najmocniej wygląda kodowanie agentowe:
- SWE-Bench Pro: 80,3% dla Fable 5 / Mythos 5 wobec 69,2% dla Opusa 4.8.
- FrontierCode Diamond: 29,3% przy najwyższym effortcie, ponad dwa razy więcej niż 13,4% Opusa 4.8.
- Terminal-Bench 2.1: 88,0% wobec 82,7% dla Opusa 4.8 i 83,4% dla GPT-5.5 z Codex CLI.
- GDPval-AA: 1932 punkty w pracy wiedzy, wobec 1890 dla Opusa 4.8 i 1769 dla GPT-5.5.
Skok na FrontierCode jest szczególnie interesujący, bo ten benchmark ma oceniać nie tylko rozwiązanie zadania, lecz także standard pracy oczekiwany w produkcyjnym repozytorium. Anthropic podkreśla też, że Fable 5 pozostaje konkurencyjny przy średnim effortcie, a więc nie każdy dobry wynik wymaga maksymalnego budżetu rozumowania.
Model poprawił również pracę z obrazem i dokumentami:
- GDP.pdf: 29,8% wobec 22,5% dla Opusa 4.8 i 24,9% dla GPT-5.5.
- Blueprint-Bench 2: 38,6% w rozumowaniu przestrzennym wobec 14,5% dla Opusa.
- OSWorld-Verified: 85,0%, minimalnie za wynikiem Mythos Preview wynoszącym 85,4%, ale przed pozostałymi modelami z tabeli.
W Humanity's Last Exam model osiąga 59,0% bez narzędzi oraz 64,5% z narzędziami. W drugim wariancie Mythos Preview pozostaje nieznacznie wyżej z wynikiem 64,7%. To dobry przykład, dlaczego nie należy sprowadzać całej premiery do hasła „wygrywa wszystko”. Fable 5 prowadzi w większości pokazanych testów, ale nie w każdym.
Uwaga na wspólną kolumnę Fable 5 i Mythos 5
Tabela wymaga uważnej lektury. Anthropic pokazuje wspólną kolumnę dla Fable 5 i Mythos 5, ponieważ w większości benchmarków wyniki różnią się najwyżej o kilka punktów procentowych. W tabeli umieszczono wyższy z dwóch rezultatów.
W testach oznaczonych gwiazdką rozbieżność może być większa. Dotyczy to między innymi cyberbezpieczeństwa i biologii, czyli dziedzin, w których publiczny Fable 5 może przełączyć zapytanie na Opusa 4.8.
Wynik 78,0% w ExploitBench opisuje zatem potencjał bazowego modelu, ale nie oznacza, że zwykły użytkownik otrzyma dostęp do tych samych możliwości w publicznym produkcie. To ważne rozróżnienie: benchmark mierzy model, a codzienne doświadczenie zależy także od klasyfikatorów, routingu i zasad dostępu.
Od odpowiedzi do wielodniowej pracy
Największa obietnica Fable 5 nie dotyczy pojedynczej odpowiedzi, lecz utrzymania jakości przez długi czas.
Anthropic twierdzi, że model potrafi planować kolejne etapy, delegować zadania subagentom, prowadzić notatki, korzystać z pamięci i sprawdzać własne wyniki. Firma opisuje go jako model przeznaczony do ambitnych, asynchronicznych projektów, które można przekazać agentowi, a następnie wrócić do gotowego rezultatu.
Podczas wczesnych testów Stripe miał użyć Fable 5 do migracji obejmującej bazę Ruby liczącą około 50 milionów linii kodu. Zadanie wykonano w jeden dzień, podczas gdy ręczna praca całego zespołu miała zająć ponad dwa miesiące. To przykład przekazany przez partnera Anthropic, a nie niezależnie powtórzony benchmark, więc należy traktować go jako studium przypadku, nie uniwersalną obietnicę.
Mimo to pokazuje zmianę skali. Agent kodujący przestaje być wyłącznie narzędziem do generowania funkcji. Ma coraz częściej:
- zrozumieć architekturę dużego systemu,
- zaplanować zmianę obejmującą wiele modułów,
- rozdzielić pracę między subagentów,
- napisać albo wykorzystać testy,
- porównać wynik z pierwotnym celem,
- naprawić problemy przed oddaniem pracy.
Więcej o samym środowisku pracy znajdziesz w naszym przewodniku po Claude Code. Warto też porównać premierę z Claude Opus 4.8, który jeszcze pod koniec maja był najmocniejszym publicznym modelem Anthropic.
Pamięć i długi kontekst mają działać razem
Samo zwiększenie okna kontekstowego nie wystarcza, jeżeli model traci cel w połowie pracy. Anthropic podkreśla więc połączenie kontekstu z narzędziem pamięci i własnymi notatkami agenta.
W eksperymencie z grą Slay the Spire dostęp do trwałej pamięci plikowej miał poprawić wyniki Fable 5 trzykrotnie mocniej niż w przypadku Opusa 4.8. Model trzy razy częściej docierał też do końcowego aktu gry. Nie jest to benchmark biznesowy, ale dobrze ilustruje problem: model musi nie tylko pamiętać fakty, lecz także wyciągać wnioski z wcześniejszych decyzji.
To może być istotne w analizach finansowych, audytach, przeglądach prawnych i rozbudowanych projektach programistycznych. Agent powinien wiedzieć nie tylko, co znajduje się w dokumentach, ale również które hipotezy już odrzucił i dlaczego.
Vision: model ma czytać wykresy, ale też oceniać własną pracę
Fable 5 ma być najmocniejszym modelem Anthropic do zadań wizualnych. Potrafi analizować szczegółowe wykresy naukowe, diagramy, tabele i dokumenty PDF. Firma pokazuje również przykłady odtwarzania aplikacji na podstawie zrzutów ekranu oraz sprawdzania, czy napisany interfejs odpowiada projektowi.
To drugie zastosowanie jest szczególnie ciekawe. Vision nie służy wtedy jedynie do odczytania obrazu. Staje się elementem pętli kontroli jakości:
- agent otrzymuje projekt albo zrzut referencyjny,
- buduje interfejs,
- uruchamia aplikację,
- ogląda rezultat,
- porównuje go z celem,
- poprawia rozbieżności.
W ten sposób model może kontrolować efekt działania kodu, zamiast oceniać wyłącznie jego tekst.
Nauka i praca wiedzy: obietnice są duże, dowody dopiero dojrzewają
Anthropic mocno eksponuje zastosowania naukowe. Wewnętrzny zespół projektowania białek miał z pomocą Mythos 5 przyspieszyć część procesu projektowania leków około dziesięciokrotnie. Firma opisuje również autonomiczny projekt genomiczny obejmujący dane milionów komórek ze 138 gatunków oraz hipotezy biologiczne, które naukowcy częściej wybierali niż propozycje modeli klasy Opus.
To brzmi imponująco, ale część wyników nie została jeszcze opublikowana w formie umożliwiającej niezależną ocenę. Anthropic zapowiada publikacje w kolejnych miesiącach. Na dziś są to przede wszystkim wyniki wewnętrzne i relacje partnerów.
W praktyce najszybciej da się zweryfikować mniej spektakularne zastosowania: analizę dokumentów, interpretację tabel, research, tworzenie raportów oraz przegląd dużych zbiorów materiałów. To właśnie tam poprawa jakości może przynieść firmom wartość wcześniej niż autonomiczne odkrycia naukowe.
Zabezpieczenia i fallback do Opusa 4.8
Klasyfikatory Fable 5 sprawdzają nie tylko ostatnią wiadomość użytkownika. Analizują także pliki, pamięć, dane z konektorów, wyniki wyszukiwania i pozostały kontekst rozmowy. Bezpieczne zapytanie może więc zostać zatrzymane, jeśli ryzykowna treść pojawi się w załączonym materiale.
W produktach Claude automatyczne przełączanie na Opusa 4.8 jest domyślnie włączone. Po zmianie modelu rozmowa pozostaje na Opusie, dopóki użytkownik ponownie nie wybierze Fable 5.
W API integrator musi obsłużyć ten mechanizm świadomie:
- odmowa jest zwracana jako poprawna odpowiedź HTTP 200 z
stop_reason: "refusal", - można skonfigurować parametr
fallbacksalbo middleware w SDK, - zapytanie zatrzymane przed wygenerowaniem treści nie jest rozliczane według ceny Fable,
- po ponowieniu na innym modelu kredyt fallbacku ogranicza podwójny koszt prompt cache.
Konserwatywne zabezpieczenia oznaczają również fałszywe alarmy. Anthropic przyznaje, że legalne testy bezpieczeństwa, edukacyjne pytania z biologii, dokumentacja firm biotechnologicznych czy nawet materiały medyczne mogą czasami uruchomić przełączenie.
Cena: dwa razy drożej od Opusa 4.8
Claude Fable 5 kosztuje 10 USD za milion tokenów wejściowych i 50 USD za milion tokenów wyjściowych. To dwukrotność standardowej ceny Opusa 4.8.
Wyższa cena nie musi jednak oznaczać dwa razy droższego zadania. Jeżeli model potrzebuje mniej prób, sam wykrywa błędy i kończy pracę w mniejszej liczbie tur, koszt całego rezultatu może być konkurencyjny. To trzeba jednak zmierzyć na własnych workflow.
Przydatne mechanizmy obniżające koszt:
- odczyt z prompt cache kosztuje 1 USD za milion tokenów,
- Batch API obniża ceny o połowę do 5 USD za wejście i 25 USD za wyjście,
- parametr
effortpozwala ograniczyć budżet rozumowania, - długi kontekst nie ma osobnej, podwyższonej stawki.
Po wznowieniu Anthropic zapowiada dostęp do Fable 5 w Claude.ai, Claude Platform, Claude Code i Claude Cowork od 1 lipca 2026 roku. W planach Pro, Max, Team i wybranych planach Enterprise model ma być czasowo dostępny w ramach do 50% tygodniowych limitów użycia do 7 lipca, a później przez usage credits. Dostęp przez AWS, Google Cloud i Microsoft Foundry ma wracać etapami.
Ważna zmiana: obowiązkowa retencja przez 30 dni
Fable 5 i Mythos 5 są objęte obowiązkową 30-dniową retencją danych na potrzeby monitorowania bezpieczeństwa. Nie są dostępne w trybie zero data retention.
Anthropic deklaruje, że dane nie będą wykorzystywane do trenowania kolejnych modeli ani do celów innych niż bezpieczeństwo. Dostęp pracowników ma być rejestrowany, a dane usuwane po 30 dniach w niemal wszystkich przypadkach.
Dla organizacji pracujących z kodem, umowami, danymi finansowymi, medycznymi lub tajemnicami przedsiębiorstwa jest to istotniejsze niż kilka punktów w benchmarku. Przed migracją należy sprawdzić:
- jakie dane będą wysyłane do modelu,
- czy polityka firmy dopuszcza 30-dniową retencję,
- czy potrzebna jest rezydencja danych w USA,
- czy Fable 5 rzeczywiście jest konieczny do danego zadania.
Dla kogo Fable 5 może mieć sens po powrocie
Po wznowieniu Fable 5 znowu staje się realną opcją dla użytkowników spoza USA. Trzeba jednak pamiętać o dwóch ograniczeniach: model nadal ma dodatkowe zabezpieczenia, a część zapytań z obszarów cyber, biologii i chemii może zostać zablokowana albo przełączona na Opusa 4.8.
Zespoły programistyczne skorzystają na migracjach, dużych implementacjach, analizie repozytoriów i wieloetapowej pracy w Claude Code. Model jest jednak drogi, więc proste poprawki nadal mogą lepiej pasować do Opusa lub Soneta.
Analitycy, prawnicy i finansiści mogą wykorzystać lepszą interpretację dokumentów, tabel, wykresów i wieloetapowych problemów. Tutaj przewaga jakości może ograniczyć liczbę ręcznych poprawek.
Zespoły budujące agentów dostają model zaprojektowany do długich, asynchronicznych zadań, z pamięcią, kompakcją kontekstu, narzędziami i budżetami zadań.
Badacze mogą docenić rozumowanie naukowe i vision, ale część legalnych zapytań z biologii lub chemii może uruchamiać fallback. Pełne możliwości Mythos 5 nadal wymagają zatwierdzonego dostępu.
Fable 5 nie jest natomiast automatycznym wyborem do codziennego czatu, streszczania krótkich tekstów czy prostych skryptów. W takich zadaniach różnica jakości może nie uzasadniać podwójnej ceny.
Co ta premiera naprawdę zmienia
Claude Fable 5 jest ważny nie dlatego, że dodaje kilka punktów do benchmarków. Po raz pierwszy Anthropic udostępnia szeroko model klasy, którą wcześniej uznawał za zbyt ryzykowną dla zwykłych użytkowników.
Firma próbuje rozwiązać ten problem nie przez osłabienie całego modelu, lecz przez warstwę klasyfikatorów i przełączanie wybranych zapytań na Opusa 4.8. To może stać się wzorem dla kolejnych premier: pełna moc w większości zastosowań, ale dynamicznie ograniczana w najbardziej wrażliwych obszarach.
Od strony możliwości Fable 5 wygląda jak duży krok naprzód w kodowaniu agentowym, vision i długiej pracy. Od strony produktu niesie jednak realne kompromisy: wyższą cenę, obowiązkową retencję oraz ryzyko fałszywych przełączeń.
Najuczciwszy werdykt po wydarzeniach z czerwca brzmi więc: Fable 5 wraca jako najmocniejszy publicznie dostępny model Anthropic, ale jego historia pokazuje, że dostęp do modeli frontier może zmieniać się nagle pod wpływem regulacji, ocen jailbreaków i decyzji infrastrukturalnych. Jego możliwości techniczne pozostają imponujące, lecz nie da się ich już oddzielić od pytań o bezpieczeństwo, kontrolę eksportu i zasady udostępniania najbardziej zaawansowanych systemów AI.


