Claude Fable 5 returns globally after the access suspension
Anthropic is restoring Claude Fable 5 globally from July 1, 2026 after US export controls were lifted. Here is what changed, how the new classifier works and when cloud access may return.

Anthropic published the specifications and benchmark methodology in its launch-day Claude Fable 5 and Mythos 5 announcement. Three days later, the model's status changed fundamentally.
On June 9, 2026, Anthropic did something it had been unwilling to do only a few weeks earlier: release a Mythos-class model to the public. It called the model Claude Fable 5 and presented it as the most capable system the company had made generally available.
Update: Fable 5 returns after export controls are lifted
On June 30, 2026, Anthropic published “Redeploying Fable 5”. The company said the export controls on Fable 5 and Mythos 5 had been lifted, and that Claude Fable 5 would return globally on July 1, 2026.
The restoration covers Claude Platform, Claude.ai, Claude Code and Claude Cowork. Access through AWS, Google Cloud and Microsoft Foundry is expected to return later as cloud partners complete their own redeployment processes.
In practice, the Fable 5 story now has three phases:
- June 9: Fable 5 and Mythos 5 launch;
- June 12: access is temporarily suspended after a US government directive;
- June 30 / July 1: export controls are lifted and Fable 5 returns globally.
Anthropic says that on June 12 it could not reliably verify user citizenship in real time, so it had to disable Fable 5 more broadly than the directive itself described. Once the controls were lifted, Fable 5 could return globally.
The company still argues that the disputed issue involved a narrow safeguards bypass rather than a universal jailbreak. It also says the tested behavior did not show unique Mythos-class capability, because less capable public models could identify similar simple vulnerabilities. Anthropic has now deployed a new classifier that it says blocks the described behavior in more than 99% of cases.
The rest of this article documents the model's capabilities, pricing, retention rules and safeguards. Launch-day details should now be read with the update in mind: Fable 5 is returning globally, while Mythos 5 remains limited to approved organizations.
This is not merely another Opus with a higher version number. Fable 5 begins the fifth generation of Claude models and is designed for problems that earlier systems could not keep in view, break into stages or reliably finish. Anthropic is talking about work that lasts for days rather than hours: large codebase migrations, deep research, document analysis, design and coordinated multi-agent projects.
The launch has a second layer that matters just as much. One underlying model is being offered as two products:
- Claude Fable 5 is broadly available but protected by additional safety classifiers.
- Claude Mythos 5 has the same core capabilities with some safeguards removed. Access is limited to approved organizations, including Project Glasswing partners.
That tension between capability and control is the most consequential part of the release.
Fable 5 at a glance
- API model:
claude-fable-5,- context window: one million tokens,
- maximum output: 128,000 tokens,
- price: $10 per million input tokens and $50 per million output tokens,
- adaptive thinking is always enabled,
- launch-day availability: Claude, Claude Code, API and major cloud platforms,
- mandatory 30-day data retention.
How Claude Fable 5 Differs From Mythos 5
Fable 5 and Mythos 5 use the same underlying model. One is not a smaller or less intelligent version of the other. They differ in distribution and safeguards.
Anthropic concluded that the new generation's capabilities in cybersecurity, biology and chemistry could substantially increase the effectiveness of malicious or insufficiently skilled users. Fable 5 therefore runs each request through additional classifiers.
If the system identifies offensive cybersecurity content, advanced biology or chemistry, or an attempt to extract the model's capabilities, the request may be handled by Claude Opus 4.8 instead. The user is told when the model switches.
Anthropic says more than 95% of early Fable sessions do not trigger fallback. For ordinary coding, document work, analysis and design, Fable 5 should therefore behave similarly to Mythos 5. The distinction becomes material in the domains covered by the stricter controls.
Before the suspension, Mythos 5 was restricted to vetted organizations. It was intended to reach Project Glasswing partners working on defensive security and critical infrastructure first. Anthropic was also preparing a limited trusted-access program for biological research.
Specifications: One Million Tokens and 128K of Output
Fable 5 supports a one-million-token context window by default. It is not an experimental header or a higher price tier that begins above 200,000 tokens. The entire window is billed at the standard model rate.
| Feature | Claude Fable 5 |
|---|---|
| API identifier | claude-fable-5 |
| Context window | 1 million tokens |
| Maximum output | 128,000 tokens |
| Reasoning mode | Adaptive thinking, always on |
| Input price | $10 / million tokens |
| Output price | $50 / million tokens |
| Prompt-cache reads | $1 / million tokens |
| Batch API | $5 input / $25 output |
| Data retention | 30 days |
A million tokens does not mean every task should receive an entire repository or company archive. Long context expands the ceiling, but it does not replace information selection. It is most valuable when an agent must revisit decisions, notes, tool results and project files across many stages of work.
Fable 5 uses adaptive thinking as its only reasoning mode. Thinking cannot be fully disabled, although developers can control its depth with the effort parameter. Raw chain of thought is never returned. The API can provide a readable reasoning summary when requested.
Benchmarks: The Largest Gains Are in Coding and Long-Horizon Work
Anthropic compares Fable 5 and Mythos 5 with Claude Opus 4.8, GPT-5.5, Gemini 3.1 Pro and the earlier Mythos Preview.
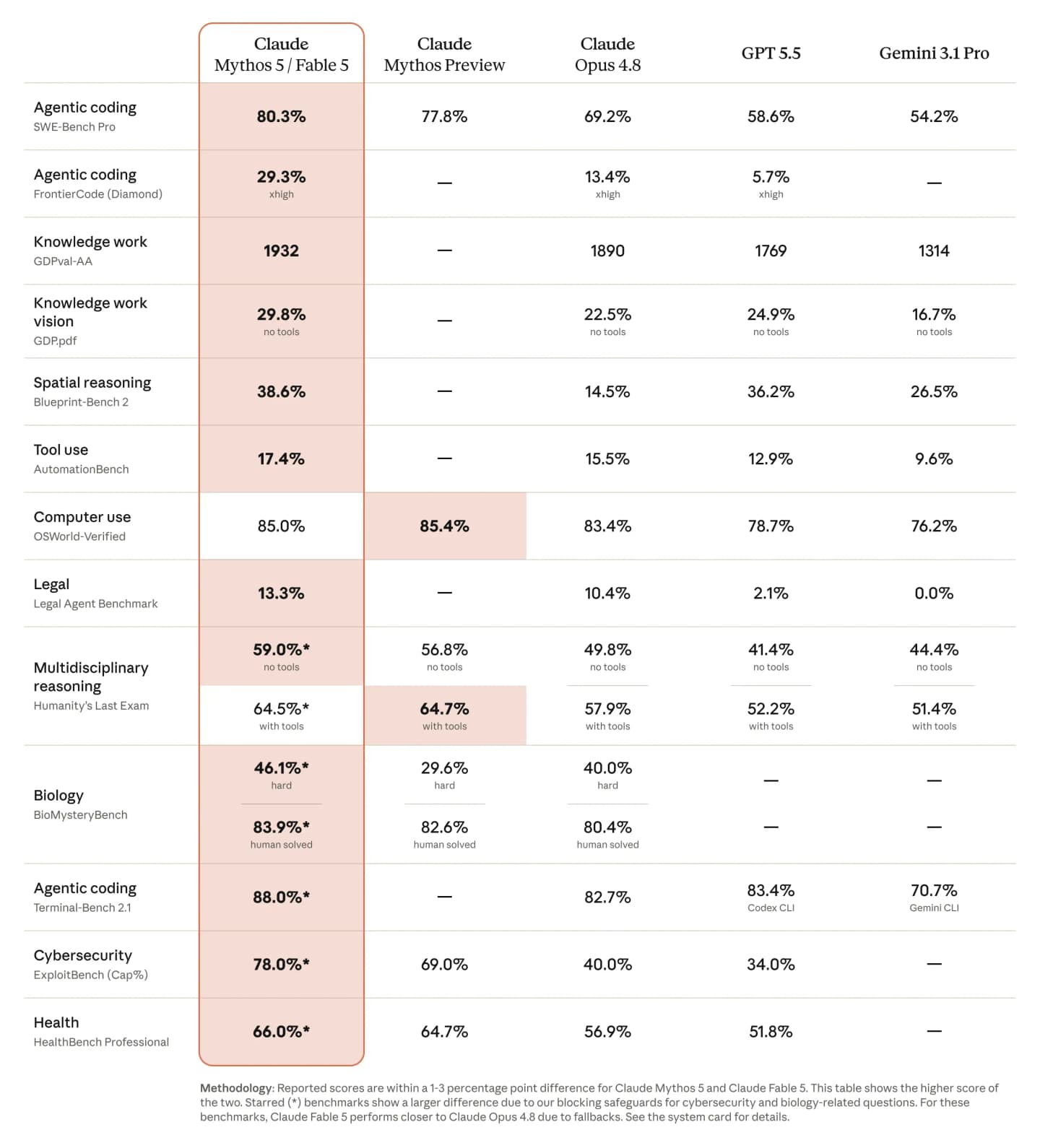
Benchmark table published by Anthropic. Fable 5 and Mythos 5 are within one to three percentage points on most evaluations, so the chart reports the higher score. Asterisks mark tests where Fable's safeguards can create a larger difference.
Agentic coding is the clearest strength:
- SWE-Bench Pro: 80.3% for Fable 5 / Mythos 5, compared with 69.2% for Opus 4.8.
- FrontierCode Diamond: 29.3% at the highest effort setting, more than twice Opus 4.8's 13.4%.
- Terminal-Bench 2.1: 88.0%, compared with 82.7% for Opus 4.8 and 83.4% for GPT-5.5 with Codex CLI.
- GDPval-AA: 1932 points on knowledge work, up from 1890 for Opus 4.8 and 1769 for GPT-5.5.
The FrontierCode gain is especially interesting because the evaluation is intended to judge not only whether a task is solved, but whether the work meets the standards of a high-quality production codebase. Anthropic also says Fable 5 remains competitive at medium effort, suggesting that every strong result does not require the maximum reasoning budget.
The model also improves on visual and document-heavy work:
- GDP.pdf: 29.8%, compared with 22.5% for Opus 4.8 and 24.9% for GPT-5.5.
- Blueprint-Bench 2: 38.6% on spatial reasoning, compared with 14.5% for Opus.
- OSWorld-Verified: 85.0%, narrowly behind Mythos Preview at 85.4% but ahead of the other models shown.
On Humanity's Last Exam, the new model reaches 59.0% without tools and 64.5% with tools. Mythos Preview remains fractionally ahead in the tool-enabled setting at 64.7%. That is a useful reminder not to flatten the release into "it wins everything." Fable leads most of the published comparisons, not every one.
Read the Shared Fable 5 / Mythos 5 Column Carefully
The benchmark chart needs interpretation. Anthropic places Fable 5 and Mythos 5 in a shared column because their scores are usually within a few percentage points. The chart displays the higher result of the two.
The gap can be larger in evaluations marked with an asterisk. These include cybersecurity and biology, the very domains where public Fable requests may fall back to Opus 4.8.
The 78.0% ExploitBench score therefore describes the potential of the underlying model. It does not mean that an ordinary Fable user receives unrestricted access to the same capability. The benchmark measures the model; the production experience also depends on classifiers, routing and access policy.
From Answering Questions to Working for Days
Fable 5's biggest promise is not a better single response. It is maintaining useful work over a much longer horizon.
Anthropic says the model can plan stages, delegate to subagents, keep notes, use persistent memory and validate its own results. The company positions it for ambitious asynchronous projects that a team can hand off and review later instead of supervising every turn.
During early access, Stripe reportedly used Fable 5 for a migration across a roughly 50-million-line Ruby codebase. The model completed the work in one day, while the equivalent manual effort was estimated at more than two months for an engineering team. This is a partner case study supplied through Anthropic, not an independently reproduced benchmark, so it should not be treated as a universal promise.
It still illustrates the intended change in scale. A coding agent is no longer being sold merely as a function generator. It is increasingly expected to:
- understand the architecture of a large system,
- plan a change spanning many modules,
- distribute work across subagents,
- write or reuse tests,
- compare the result with the original objective,
- correct problems before handing the work back.
Our evergreen Claude Code guide explains the working environment in more detail. It is also worth comparing this release with Claude Opus 4.8, which was Anthropic's strongest public model as recently as late May.
Memory and Long Context Are Supposed to Work Together
A larger context window is not enough if a model loses the objective halfway through a project. Anthropic is therefore emphasizing the combination of context, persistent file-based memory and the agent's own notes.
In an experiment using the deck-building game Slay the Spire, persistent memory improved Fable 5's performance three times more than it improved Opus 4.8. Fable also reached the final act three times as often. This is not a business benchmark, but it demonstrates the underlying problem well: a model needs to learn from its previous decisions, not merely retain facts.
That may matter in financial analysis, audits, legal review and long software projects. A useful agent should remember not only what a document says, but which hypotheses it has already rejected and why.
Vision Is Becoming Part of the Quality-Control Loop
Fable 5 is Anthropic's strongest model for visual tasks. It can read dense scientific figures, diagrams, tables and PDFs. Anthropic also demonstrates rebuilding applications from screenshots and checking whether an implemented interface matches its original design.
The second use case is particularly important. Vision is no longer just a way to read an image. It becomes part of a verification loop:
- the agent receives a design or reference screenshot,
- builds the interface,
- runs the application,
- inspects the result,
- compares it with the goal,
- fixes visible differences.
This lets the model assess what its code actually produced rather than reviewing source text alone.
Science and Knowledge Work: Big Claims, Evidence Still Maturing
Anthropic places considerable emphasis on scientific use. Its internal protein-design team reportedly accelerated parts of drug design by roughly ten times with Mythos 5. The company also describes an autonomous genomics project involving millions of cells from 138 animal species and biological hypotheses that researchers preferred over those from Opus-class models.
These results are striking, but some have not yet been published in a form that allows independent evaluation. Anthropic says publications will follow in the coming months. For now, they remain largely internal results and partner reports.
The less spectacular applications will be easier to validate first: document analysis, chart interpretation, research, report creation and review of large evidence sets. That is where better knowledge-work performance may produce business value before autonomous scientific discovery does.
Safeguards and the Opus 4.8 Fallback
Fable's classifiers inspect more than the user's latest message. They also review files, memory, connector content, web results and the rest of the conversation. A benign prompt can therefore be flagged because sensitive material appears elsewhere in the context.
Automatic switching to Opus 4.8 is enabled by default in Claude products. After a switch, the conversation remains on Opus until the user selects Fable again.
API integrations must handle this behavior deliberately:
- a refusal is returned as a successful HTTP 200 response with
stop_reason: "refusal", - developers can configure the
fallbacksparameter or SDK middleware, - a request stopped before output begins is not billed at Fable rates,
- fallback credit helps avoid paying the prompt-cache switching cost twice.
Conservative controls also create false positives. Anthropic acknowledges that authorized security testing, educational biology, biotech documentation and medical material can sometimes trigger a switch.
Pricing: Twice the Standard Cost of Opus 4.8
Claude Fable 5 costs $10 per million input tokens and $50 per million output tokens, twice the standard price of Opus 4.8.
That does not necessarily make every completed task twice as expensive. If the model needs fewer attempts, catches its own mistakes and finishes in fewer turns, its total cost per useful result may still be competitive. Teams will need to measure that on their own workflows.
Cost-saving mechanisms include:
- prompt-cache reads at $1 per million tokens,
- 50% Batch API pricing at $5 input and $25 output,
- the
effortparameter for controlling reasoning depth, - standard pricing across the entire long-context window.
After redeployment, Anthropic says Fable 5 returns to Claude.ai, Claude Platform, Claude Code and Claude Cowork on July 1, 2026. Pro, Max, Team and selected Enterprise plans get access within up to 50% of weekly usage limits through July 7, after which use moves to usage credits. Access through AWS, Google Cloud and Microsoft Foundry will return in phases.
The 30-Day Data-Retention Requirement Matters
Fable 5 and Mythos 5 require 30-day data retention for safety monitoring. Neither model is available under zero data retention.
Anthropic says the data will not be used to train future Claude models or for purposes unrelated to safety. Human access is logged, and data is deleted after 30 days in almost all cases.
For organizations handling source code, contracts, financial records, medical data or trade secrets, this may matter more than a benchmark gain. Before migrating, teams should verify:
- what information will be sent to the model,
- whether internal policy permits 30-day retention,
- whether US-only inference is required,
- whether Fable 5 is actually necessary for the workload.
Who Could Benefit From Fable 5's Return
With redeployment, Fable 5 is again a practical option for users outside the United States. Two caveats remain: the model still has additional safeguards, and some cyber, biology or chemistry requests may be refused or routed to Opus 4.8.
Software teams stand to benefit on migrations, large implementations, repository analysis and multi-stage Claude Code work. The model is expensive, so straightforward fixes may still be better suited to Opus or Sonnet.
Analysts, legal teams and finance professionals may benefit from better interpretation of documents, tables, charts and multi-step problems. The value will depend on whether the model reduces review and correction time.
Agent builders get a model designed around long-running asynchronous tasks, with memory, context compaction, tools and task budgets.
Researchers may value its scientific reasoning and vision, but legitimate biology or chemistry requests can still trigger fallback. Full Mythos 5 capabilities continue to require approved access.
Fable 5 is not an automatic choice for everyday chat, short summaries or simple scripts. In those cases, the quality difference may not justify twice the token price.
What This Launch Actually Changes
Claude Fable 5 matters because Anthropic is broadly releasing a capability class it previously considered too risky for ordinary access.
The company is trying to solve that problem without weakening the model across the board. Instead, it adds classifiers and routes selected requests to Opus 4.8. This may become a pattern for future frontier releases: full capability for most work, dynamically restricted in the most sensitive areas.
On capability, Fable 5 looks like a substantial step forward in agentic coding, vision and long-horizon work. As a product, it comes with real trade-offs: higher pricing, mandatory retention and the possibility of false-positive model switches.
The fairest verdict after the June events is therefore: Fable 5 is returning as Anthropic's strongest publicly available model, but its rollout shows how quickly access to frontier systems can change under regulation, jailbreak evaluation and infrastructure decisions. Its technical capabilities remain noteworthy, yet they can no longer be separated from questions about safety, export controls and who gets to use the most capable AI systems.


